
3. 엑셀 파일 다루기 Last updated: 2023-10-17 10:30:34
이 장에서는 파이썬을 이용해 엑셀 파일을 다루는 방법에 대해 알아보자. 엑셀 데이터를 저장하는데 가장 많이 사용하는 판다스의 DataFrame을 이용해 설명한다.
이 장에서는 파이썬을 이용해 엑셀 파일을 다루는 방법에 대해 알아보자. 엑셀 데이터를 저장하는데 가장 많이 사용하는 판다스의 DataFrame을 이용해 설명한다.
파이썬을 엑셀을 다루려면 openpyxl 이라는 모듈을 설치해야 한다.
$ pip install openpyxl설치가 완료되었다면 openpyxl 파일이 정상적으로 설치되었는지 임포트해서 확인한다.
[예제 6- 57] openpyxl 모듈 import 확인하기
import openpyxl
openpyxl.__version__[결과]
'3.0.7'설치된 버전 정보가 출력 된다면 정상적으로 설치된 것이다.
우선 엑셀 파일을 다루려면 엑셀의 구성에 대해 이해할 필요가 있다. 엑셀은 아래 그림과 같이 하나의 파일은 하나의 문서(document)를 의미한다. 하나의 문서 안에는 여러 개의 시트(sheet)로 구성되고, 각 시트는 식별 가능한 이름을 갖는다. 하나의 시트는 2차원으로 배치된 여러 개의 셀(cell)로 구성되어 있다. 각 셀의 열은 ‘A’부터 시작하는 문자로, 행은 1부터 증가하는 숫자로 셀의 위치를 지정한다. 만일 첫 번째 열, 첫 번째 행이라면 ‘A1’로, 세 번째 열, 네 번째 행이라면 ‘C4’로 셀의 위치를 지정해 값을 지정하거나 가져올 수 있다.
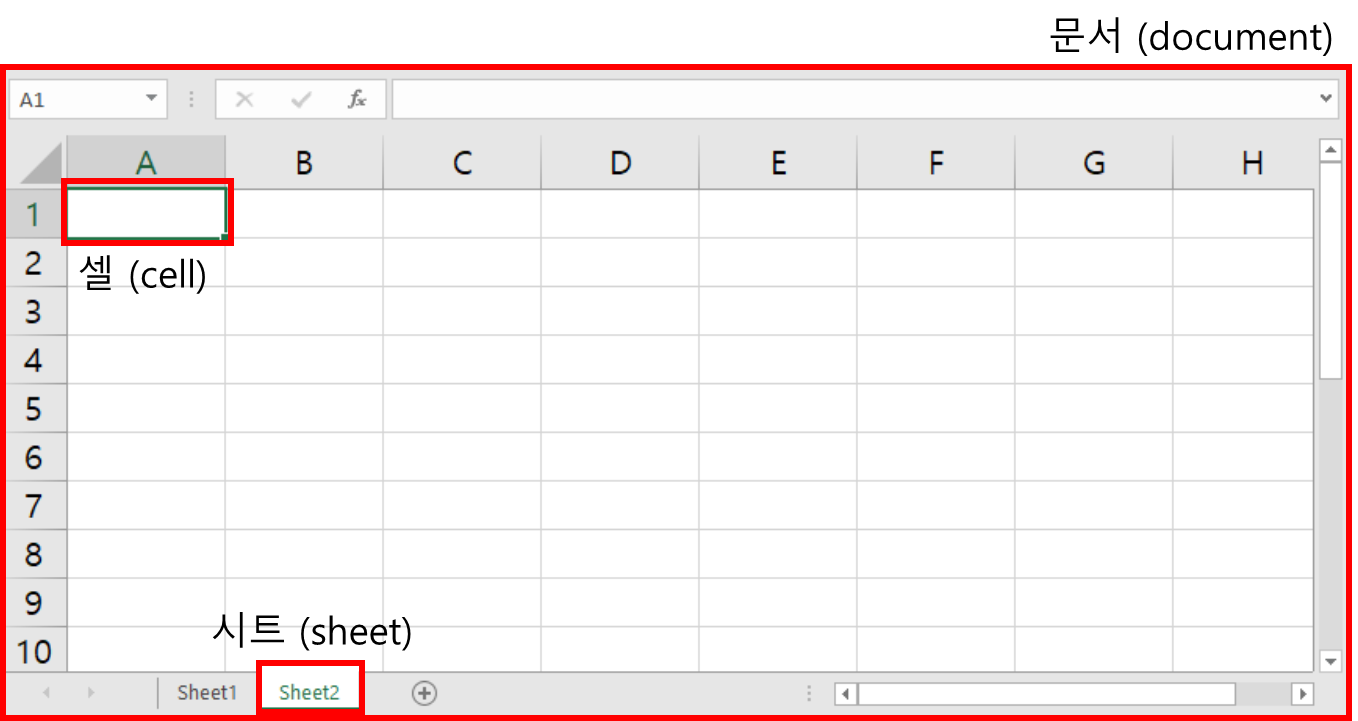
[그림 6-3-1] 엑셀의 문서 구조
이제 엑셀 파일을 읽어보자. 다음은 전세계 GDP 상위 20개국에 대한 엑셀 파일의 예시이다.
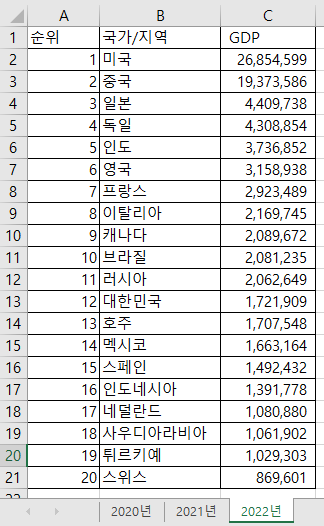
[그림 6-3-2] World GDP.xlsx 파일 내용
[예제 6- 58] 엑셀 시트 이름 얻어오기
# [1] openpyxl 모듈 import
from openpyxl import load_workbook
# [2] 엑셀 파일 읽어오기
wb = load_workbook("World GDP.xlsx")
# [3] 엑셀 문서의 시트 정보 출력
print(wb.sheetnames)
print(wb.sheetnames[-1])[결과]
['2020년', '2021년', '2022년']
2022년위 예제에 대해 설명한다.
[1]에서 엑셀 파일을 다루는데 필요한 openpyxl 모듈을 import 한다. 특히 파일을 읽어오는 함수인 load_workbook 모듈을 사용한다.
[2]에서 엑셀 파일의 경로를 지정하고 파일을 읽어온다. 읽어온 워크북(workbook) 객체는 wb 변수에 저장한다.
[3]에서 워크북 객체의 sheetnames 변수를 출력해 읽어온 엑셀 문서의 시트 이름을 출력한다. 결과를 확인해보면 ‘2020년’, ‘2021년’, ‘2022년’의 3개 시트가 있다. 마지막 시트를 출력하면 ‘2022년’ 시트이다.
시트 객체를 얻어오려면 다음과 같이 워크북(workbook) 객체에서 시트 이름을 배열형 변수에 입력한다.
[예제 6- 59] 엑셀 시트의 셀값 얻어오기
# [1] 시트 객체 얻어오기
ws = wb[wb.sheetnames[-1]]
# [2] 첫 번째줄의 헤더 값 읽어오기
ws['A1'].value, ws['B1'].value, ws['C1'].value[결과]
('순위', '국가/지역', 'GDP')위 예제에 대해 설명한다.
[1]에서 wb 객체에 원하는 시트 이름을 입력하면 해당 시트를 얻어올 수 있다. 읽어온 시트 객체를 ws 변수에 저장한다.
[2]에서 시트의 값을 셀 위치를 지정하여 가져온다. 헤더 부분에 해당하는 ‘A1’ ~ ‘C1’까지 값을 가져와 출력해 본다.
읽어온 엑셀 시트에서 데이터가 위치하는 최대 범위를 얻어오려면 Worksheet 객체의 max_row와 max_column 변수를 이용한다.
[예제 6- 60] 엑셀 시트의 데이터 범위 얻어오기
print(ws.max_row, "행 x", ws.max_column, "열")[결과]
21 행 x 3 열셀의 값을 가져오려면 셀의 위치를 알아야 한다. 엑셀에서 셀의 위치를 지정하는 방법은 다음의 두 가지 이다.
워크시트에서 셀의 위치를 이용해 값을 가져오는 방법에 대해 설명한다.
형식 | worksheet[column_position + row_position] |
|---|---|
파라미터 | • worksheet : 접근할 워크시트 객체를 전달한다. |
예시 | worksheet[’A1’] : 1열, 1행 |
워크시트 객체에 셀의 위치를 나타내는 문자열(예: ‘A1’)을 키로 활용해 딕셔너리와 같이 값을 얻어온다. 엑셀에서 컬럼은 ‘A’, ‘B’, …. ‘AA’, ‘AB’, …. ‘ZZ’, … 하는 식으로 문자열로 위치를 지정한다. 이 방법은 행과 열을 붙여서 입력하거나 컬럼의 문자열을 이미 알고 있다면 매우 유용한다.
다음은 시트에서 각 줄의 값을 읽어와 출력하는 예제이다.
[예제 6- 61] 시트의 줄 단위 값 출력하기
# [1] 2행부터 21행까지 반복
for i in range(2, 22):
# [2] 각 행의 A, B, C열의 값을 출력
print(f"({ws['A'+str(i)].value}) {ws['B'+str(i)].value} : {ws['C'+str(i)].value:,}")[결과]
(1) 미국: 26,854,599
(2) 중국: 19,373,586
(3) 일본: 4,409,738
(4) 독일: 4,308,854
(5) 인도: 3,736,852
(6) 영국: 3,158,938
(7) 프랑스: 2,923,489
(8) 이탈리아: 2,169,745
(9) 캐나다: 2,089,672
(10) 브라질: 2,081,235
(11) 러시아: 2,062,649
(12) 대한민국: 1,721,909
(13) 호주: 1,707,548
(14) 멕시코: 1,663,164
(15) 스페인: 1,492,432
(16) 인도네시아: 1,391,778
(17) 네덜란드: 1,080,880
(18) 사우디아라비아: 1,061,902
(19) 튀르키예: 1,029,303
(20) 스위스: 869,601위 예제에 대해 설명한다.
[1]에서 읽어올 행을 반복한다.
[2]에서 각 행의 A열, B열, C열에 해당하는 값을 가져와 문자열로 출력한다.
워크시트에서 셀의 열과 행에 해당하는 인덱스를 이용해 셀 값을 가져오는 방법에 대해 설명한다.
형식 | worksheet.cell(row_index, col_index) |
|---|---|
파라미터 | • worksheet : 워크시트 객체를 전달한다. |
예시 | worksheet.cell(1, 1) ⇒ 1행 1열 |
cell( ) 함수를 이용해 문자가 아닌 행과 열의 숫자를 입력하여 셀 값을 가져온다. 행과 열 모두 숫자형이기 때문에 반복문을 사용하기에 용이하다.
다음은 cell( ) 함수를 이용해 셀의 값을 가져오는 예제이다.
[예제 6- 62] cell( ) 함수로 셀값 얻어오기
# [1] 2행부터 21행까지 반복
for i in range(2, 22):
# [2] 각 행의 1, 2, 3열의 값을 출력
print(f"({ws.cell(i, 1).value}) {ws.cell(i, 2).value}: {ws.cell(i, 3).value:,}")[결과]
(1) 미국: 26,854,599
(2) 중국: 19,373,586
(3) 일본: 4,409,738
(4) 독일: 4,308,854
(5) 인도: 3,736,852
(6) 영국: 3,158,938
(7) 프랑스: 2,923,489
(8) 이탈리아: 2,169,745
(9) 캐나다: 2,089,672
(10) 브라질: 2,081,235
(11) 러시아: 2,062,649
(12) 대한민국: 1,721,909
(13) 호주: 1,707,548
(14) 멕시코: 1,663,164
(15) 스페인: 1,492,432
(16) 인도네시아: 1,391,778
(17) 네덜란드: 1,080,880
(18) 사우디아라비아: 1,061,902
(19) 튀르키예: 1,029,303
(20) 스위스: 869,601위 예제에 대해 설명한다.
[1]에서 읽어올 행을 반복한다.
[2]에서 각 행의 1열, 2열, 3열에 해당하는 값을 가져와 문자열로 출력한다.
판다스는 다양한 형식의 데이터를 DataFrame으로 읽어오는 쉬운 방법을 제공한다. read_excel( ) 함수를 이용해 엑셀 파일명과 시트명을 지정하면 시트에 있는 모든 데이터를 읽어온다. 다음은 판다스를 이용해 데이터를 읽어오는 예시이다.
[예제 6- 63] 판다스로 엑셀 시트 얻어오기
# [1] pandas 모듈 import
import pandas as pd
# [2] 엑셀 파일에서 시트의 내용을 읽어오기
df = pd.read_excel('World GDP.xlsx', sheet_name=wb.sheetnames[-1])
print(df)[결과]
순위 국가/지역 GDP
0 1 미국 26854599
1 2 중국 19373586
2 3 일본 4409738
3 4 독일 4308854
4 5 인도 3736852
5 6 영국 3158938
6 7 프랑스 2923489
7 8 이탈리아 2169745
8 9 캐나다 2089672
9 10 브라질 2081235
10 11 러시아 2062649
11 12 대한민국 1721909
12 13 호주 1707548
13 14 멕시코 1663164
14 15 스페인 1492432
15 16 인도네시아 1391778
16 17 네덜란드 1080880
17 18 사우디아라비아1061902
18 19 튀르키예 1029303
19 20 스위스 869601위 예제에 대해 설명한다.
[1]에서 판다스 모듈을 import 한다.
[2]에서 read_excel( ) 함수를 이용해 엑셀 파일을 읽어온다. 여기서는 파일명과 시트 이름을 입력하였으므로 해당 시트의 모든 데이터를 읽어서 df 변수에 DataFrame 형식으로 저장한다.
시트에서 일부 영역 데이터를 읽어오는 방법에 대해 알아보자. 특히 엑셀 시트의 맨 윗줄 부터 읽어오는 방법이다. read_excel( ) 함수를 이용해 데이터를 읽어올 때 usecols 인자에 원하는 컬럼을 지정한다. 읽어올 행 수는 nrows 인자에 숫자로 입력한다. 아래 그림을 보면 사용할 컬럼은 A ~ C까지 이다. 따라서 usecols 인자에 ‘A:B’ 라고 입력하거나 ‘A,B,C’ 라고 입력한다. 읽어올 행은 헤더를 제외하고 10개이다. 따라서 2번행 부터 11번 행까지 10개의 행을 읽어온다.
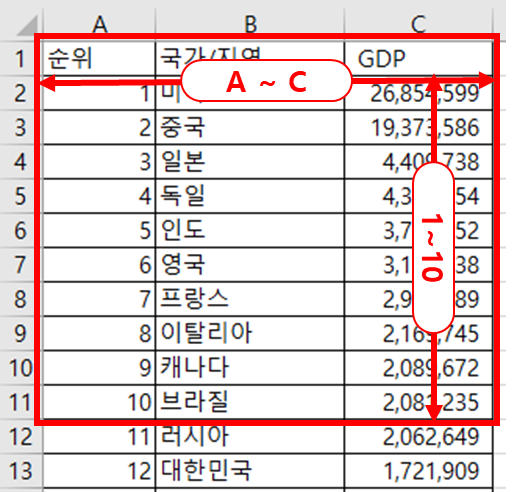
[그림 6-3-3] 엑셀 파일을 읽어올 때 행과 열의 의미
다음은 시트에서 읽어올 영역을 지정하여 데이터를 읽어오는 예시이다.
[예제 6- 64] 영역 지정해서 판다스의 DataFrame으로 값 읽어오기
# [1] pandas 모듈 import
import pandas as pd
# [2] 엑셀 파일에서 시트의 내용을 읽어오기
df = pd.read_excel('World GDP.xlsx', sheet_name=wb.sheetnames[-1], usecols="A:C", nrows=10)
df[결과]
순위 국가/지역 GDP
0 1 미국 26854599
1 2 중국 19373586
2 3 일본 4409738
3 4 독일 4308854
4 5 인도 3736852
5 6 영국 3158938
6 7 프랑스 2923489
7 8 이탈리아 2169745
8 9 캐나다 2089672
9 10 브라질 2081235위 예제에 대해 설명한다.
[1]에서 pandas 모듈을 import 한다.
[2]에서 엑셀 파일을 읽어온다. 이 때 sheet_name에 읽어올 시트 이름을 문자열로 입력하고, usecols에 열의 문자열을 범위 혹은 목록 형태로 입력한다.
아래 그림과 같이 데이터를 맨 윗줄 부터가 아니라 몇 줄을 띄운 후 읽어오려면 skiprows 인자를 이용한다. 다만 항상 읽어오는 첫 줄이 헤더가 되므로 읽어온 DataFrame에서 헤더에 해당하는 컬럼명을 수정해 주어야 한다.
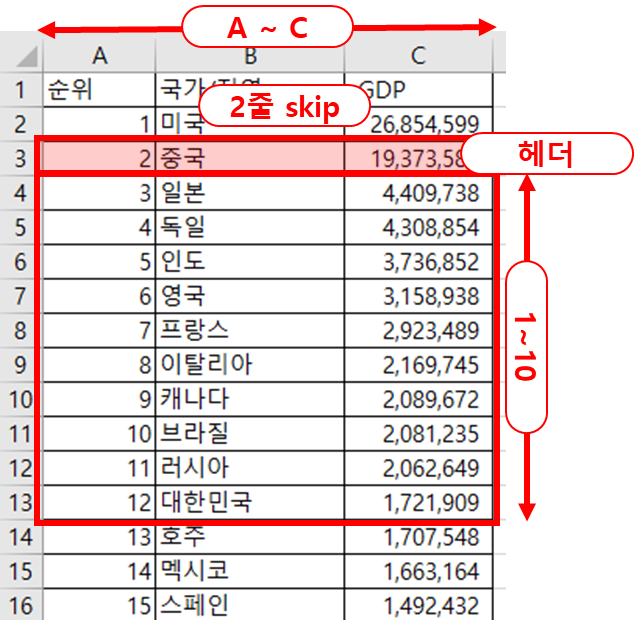
[그림 6-3-4] 엑셀 파일 읽어올 때 skiprows 지정에 따른 행번호
[예제 6- 65] 판다스로 엑셀 파일 읽어올 때 줄 수 지정하기
# [1] pandas 모듈 import
import pandas as pd
# [2] 엑셀 파일에서 시트의 내용을 읽어오기
df = pd.read_excel('World GDP.xlsx', sheet_name=wb.sheetnames[-1], usecols="A:C", nrows=10, skiprows=2)
# [3] DataFrame 컬럼 이름 지정
df.columns = ['순위', '국가/지역', 'GDP']
df[결과]
순위 국가/지역 GDP
0 3 일본 4409738
1 4 독일 4308854
2 5 인도 3736852
3 6 영국 3158938
4 7 프랑스 2923489
5 8 이탈리아 2169745
6 9 캐나다 2089672
7 10 브라질 2081235
8 11 러시아 2062649
9 12 대한민국 1721909위 예제에 대해 설명한다.
[1]에서 pandas 모듈을 임포트 한다.
[2]에서 엑셀 파일을 읽어온다. 이 때 읽어올 컬럼은 usecols 변수에 “A:C”라고 입력하여 A~C의 3개 컬럼을 읽어오도록 했다. nrows값으로 10을 입력해 헤더를 제외하고 총 10행을 읽어오도록 했다. skiprows 인자는 처음 몇 행을 읽지 않고 건너 뛰도록 한다. 우리는 2값을 주어 1~2행을 건너뛰고 3행을 헤더로, 4행 ~ 13행을 데이터로 읽어온다.
[3]에서 DataFrame의 컬럼 이름을 지정한다. 왜냐하면 읽어온 데이터는 3행을 헤더로 사용하는데 이는 우리가 원하는 값이 아니다.
Hint ! 판다스로 엑셀 파일 읽기
판다스에서 엑셀 파일을 읽어오는 read_excel( ) 함수에 대한 더 자세한 내용은 아래 홈페이지를 참조하기 바란다.
https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html
엑셀 파일을 생성하고 저장하는 방법은 앞에서 우선 Workbook 객체를 생성하고 Worksheet를 생성 혹은 선택한 후 워크시트의 셀에 값을 지정한 후 Workbook 객체를 파일로 저장하면 된다.
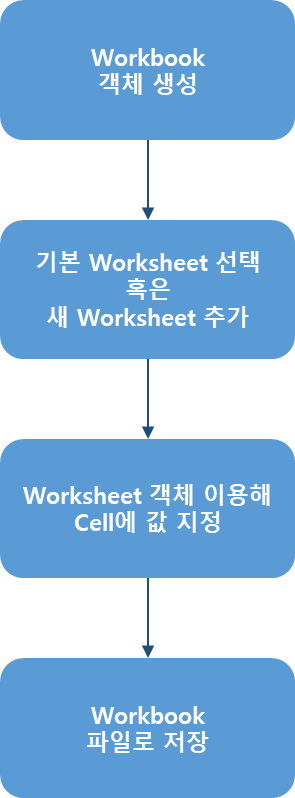
[그림 6-3-5] 엑셀 파일 읽어서 처리하는 과정
다음은 Workbook을 생성하고 기본 Sheet에 문자열을 입력하고 저장하는 간단한 예제이다.
[예제 6- 66] 셀에 값 입력하고 엑셀 파일 저장하기
# [1] openpyxl 모듈 import
from openpyxl import Workbook
# [2] 새로운 Workbook 객체 생성
wb = Workbook()
# [3] 디폴트 Worksheet 얻어오기
ws = wb.active
# [4] Worksheet에 텍스트 문자열 입력
ws['A1'] = 'Hello Python'
# [5] Workbook 파일로 저장
wb.save(#write_test1.xlsx#)[결과]
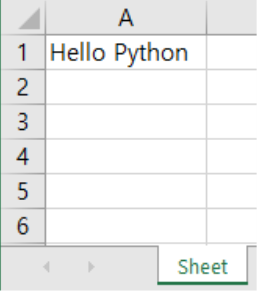
[그림 6-3-6] 엑셀 텍스트 입력 결과
위 예제에 대해 설명한다.
• [1]에서 openpyxl 모듈을 임포트한다.
• [2]에서 새로운 Workbook 객체를 생성한다.
• [3]에서 기본으로 생성된 Worksheet 객체를 가져온다. Workbook이 생성되면 무조건 기본적으로 시트가 하나 생성되며 시트 이름은 ‘Sheet’ 이다. 기본적을 생성된 시트는 현재 활성화 되어 있기 때문에 Workbook.active 변수로 얻어올 수 있다.
• [4]에서 워크시트의 특정 위치(A열, 1행)에 ‘Hello Python’이라는 문자를 할당했다.
• [5]에서 지금까지 작성된 Workbook을 save( ) 함수를 이용해 ‘write_test1.xlsx’라는 이름의 엑셀 파일로 저장한다.
셀에 값을 입력하려면 셀의 위치를 지정해야 한다. openpyxl은 셀의 위치를 지정하고 값을 설정할 수 있는 인터페이스를 제공한다. 셀에 값을 입력하는 방법은 다양한다. 아래 예제를 확인하고 알맞은 방법을 적용하면 된다.
[예제 6- 67] 셀에 값을 입력하는 다양한 방법 사용하기
# [1] openpyxl 모듈 import
from openpyxl import Workbook
from openpyxl.styles.fonts import Font
# [2] Workbook 개체 생성, 기본 Worksheet 얻어오기
wb = Workbook()
ws = wb.active
# [3] 셀에 문자 입력 및 폰트 지정
ws["A1"].value = "A1 Cell Value"
ws["A2"] = "A2 Cell Value"
ws.cell(3,1).value = "A3 Cell Value"
ws.cell(row=4, column=1).value = "A4 Cell Value"
# [5] 엑셀 파일 저장
wb.save("write_test3.xlsx")[결과]
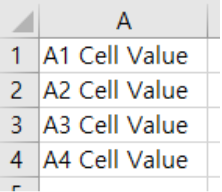
[그림 6-3-7] 엑셀에 값을 입력하는 여러 방법 결과
위의 예제와 동일하지만 이번에는 기본 Worksheet가 아닐 원하는 이름의 시트를 새로 생성해 작성 후 엑셀 파일을 저장해 본다.
[예제 6- 68] 시트 추가해서 파일 저장하기
# [1] openpyxl 모듈 import
from openpyxl import Workbook
# [2] 새로운 Workbook 객체 생성
wb = Workbook()
# [3] 디폴트 Worksheet 얻어오기
ws = wb.create_sheet('New Sheet', 0)
# [4] Worksheet에 텍스트 문자열 입력
ws['A1'] = 'Welcome Python'
# [5] Workbook 파일로 저장
wb.save("write_test2.xlsx")위 예제에 대해 설명한다.
[1]에서 openpyxl 모듈을 임포트한다.
[2]에서 새로운 Workbook 객체를 생성한다.
[3]에서 ‘New Sheet’라는 이름의 Worksheet를 새로 생성해 ws라는 변수에 저장한다. 시트 위치는 맨 앞에 위치 시키기 위해 0값을 입력했다.
[4]에서 워크시트의 특정 위치(A열, 1행)에 ‘Welcome Python’이라는 문자를 할당했다.
[5]에서 지금까지 작성된 Workbook을 save( ) 함수를 이용해 ‘write_test2.xlsx’라는 이름의 엑셀 파일로 저장한다.
아래는 실제 저장된 파일의 내용이다. ‘New Sheet’라는 이름의 생성되어 있다. 위치는 ‘Sheet’ 시트보다 앞이다. ‘A1’ 위치에 ‘Welcome Python’이라는 문자열도 입력되어 있다.
[결과]
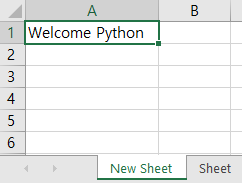
[그림 6-3-8] 엑셀에 새로운 시트 생성
엑셀은 단순히 셀에 텍스르를 입력하는 것 뿐만 아니라, 수식을 입력하거나 글자색이나 크기를 조정하고, 셀의 외곽선을 그리는 등 다양한 스타일 작업을 할 수 있다. 이제 다양한 방식으로 엑셀의 내용을 작성해 보다 보기 좋은 엑셀파일을 만드는 방법에 대해 알아보도록 한다.
셀에는 Font 객체를 이용해 글자 크기, 굵기, 색, 폰트 등을 지정할 수 있다. 다음은 셀에 글자를 입력하고 폰트를 지정하는 예제이다.
[예제 6- 69] 셀에 폰트 지정하기
# [1] openpyxl 모듈 import
from openpyxl import Workbook
from openpyxl.styles.fonts import Font
# [2] Workbook 개체 생성, 기본 Worksheet 얻어오기
wb = Workbook()
ws = wb.active
# [3] 셀에 문자 입력 및 폰트 지정
ws["A1"].value = "Python Programming"
ws["A1"].font = Font(size=16, bold=True, color='000000FF')
# [4] 셀에 문자 입력 및 폰트 지정
ws["A2"].value = "Data Analytics"
ws["A2"].font = Font(size=12, name='Arial Narrow', color='00FF0000')
# [5] 엑셀 파일 저장
wb.save("style_test1.xlsx")[결과]
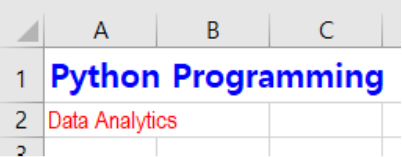
[그림 6-3-9] 엑셀 시트에 폰트 스타일 적용
위 예제에 대해 설명한다.
[1]에서 openpyxl 모듈을 임포트한다. 이 때 Font 객체도 함께 임포트 한다.
[2]에서 Workbook 객체를 생성하고 기본 Worksheet를 가져온다.
[3]에서 'A1' 위치에 글자를 입력하고 Font 객체를 이용해 글자 스타일을 지정한다. size는 글자크기로 16을 지정하고, bold를 True로 하여 굵게, color은 글자색으로 '0000FF'로 파란색이다. (글자색은 aRGB에 해당하는 8자리 문자열로 '00000000' ~ 'FFFFFFFF'로 첫 번째 두자는 alpha(투명도), 다음 두 자리는 Red, 다음 두 자리는 Green, 마지막 두 자리는 Blue에 해당하는 16진수 값으로 지정하면 됩니다)
[4] 에서 'A2' 위치에 글자를 입력하고 Font 객체를 이용해 글자 스타일을 지정한다. size는 글자 크기로 12를 지정하고, 폰트는 'Arial Narrow'를 지정하고, 글자색은 'FF0000'로 빨간색이다.
[5]에서 작성한 엑셀을 파일로 저장한다.
저장된 엑셀 파일을 확인해보면 아래와 같다. 첫 줄(’A1’)에 파란색으로 ‘Python Programming’이라고 적혀 있고, 두 번째 줄(’B1’)에 빨간색으로 ‘Data Analytics’라고 적혀 있다.
Font 객체는 다음과 같은 다양한 속성을 갖는다.
[표 8] 엑셀 Font 속성
인자 | 속성 |
name | 폰트 이름 |
size | 글자 크기 |
italic | 글자 기울기 여부, True 혹은 False |
vertAlign | 세로 글자 배열, 위첨자, 아래첨자 등 스타일 |
underline | 밑줄 |
strike | 취소선 여부, True 혹은 False |
color | 글자색 |
셀의 크기와 정렬 옵션을 지정하는 방법에 대해 알아보자. 다음은 셀에 문자열을 입력하고, 폰트 스타일 지정 및 셀의 너비와 높이, 문자열 정렬을 지정하는 예제이다.
[예제 6- 70] 셀 크기와 글자 정렬하기
# [1] openpyxl 모듈 import
from openpyxl import Workbook
from openpyxl.styles.fonts import Font
from openpyxl.styles import Alignment
# [2] Workbook 개체 생성, 기본 Worksheet 얻어오기
wb = Workbook()
ws = wb.active
# [3] 셀에 문자 입력 및 폰트 지정
ws["A1"].value = "Python Programming"
ws["A1"].font = Font(size=16, bold=True, color='000000FF')
# [4] 셀 정렬과 높이/너비 지정
ws['A1'].alignment = Alignment(horizontal='right', vertical='center')
ws.row_dimensions[1].height = 100
ws.column_dimensions['A'].width = 40
# [5] 셀에 문자 입력 및 폰트 지정
ws["A2"].value = "Data Analytics"
ws["A2"].font = Font(size=12, name='Arial Narrow', color='00FF0000', vertAlign='baseline')
# [6] 셀 정렬과 너비 지정
ws['A2'].alignment = Alignment(horizontal='center', vertical='bottom')
ws.row_dimensions[2].height = 40
# [7] 엑셀 파일 저장
wb.save("style_test2.xlsx")[결과]
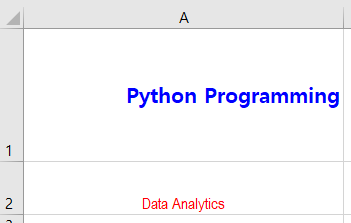
[그림 6-3-10] 엑셀 시트의 셀 크기 조정
위 예제에 대해 설명한다.
[1]에서 openpyxl 모듈을 임포트한다. 이 때 Font 객체도 함께 임포트 한다.
[2]에서 Workbook 객체를 생성하고 기본 Worksheet를 가져온다.
[3]에서 ‘A1’ 위치에 글자를 입력하고 Font 객체를 이용해 글자 스타일을 지정한다. 폰트 크기는 16으로 지정하고, 굵게, 글자 색은 파란색으로 지정한다.
[4]에서 ‘A1’셀의 가로는 우측 정렬, 세로는 중앙 정렬, 높이는 100, 너비는 40으로 지정한다.
[5] 에서 ‘A2’ 위치에 글자를 입력하고 Font 객체를 이용해 글자 스타일을 지정한다. 폰트 크기는 12, 폰트는 ‘Arial Narrow’, 글자색은 빨간색, 글자 세로 기준은 기본으로 지정한다.
[6]에서 ‘A2’셀의 가로 정렬은 가운데로, 세로 정렬은 아래로, 높이는 40으로 지정한다.
[7]에서 작성한 엑셀을 파일로 저장한다.
셀 정렬을 위해 사용되는 Aligment의 자세한 내용은 아래 링크를 참조하기 바란다.
셀의 테두리선과 배경색 등을 지정하는 방법에 대해 알아보도록 한다.
[예제 6- 71] 셀 테두리 및 배경 스타일 지정하기
# [1] 모듈 임포트
from openpyxl import Workbook
from openpyxl.styles import Border, Side
from openpyxl.styles import PatternFill
from openpyxl.styles.colors import Color
# [2] Workbook 개체 생성, 기본 Worksheet 얻어오기
wb = Workbook()
ws = wb.active
# [3] 셀에 값 입력
ws["B2"].value = "Name"
ws["C2"].value = "Age"
ws["D2"].value = "Height"
ws["B3"].value = "손흥민"
ws["B4"].value = "이강인"
ws["C3"].value = 31
ws["C4"].value = 22
ws["D3"].value = 183
ws["D4"].value = 173
# [4] 스타일 객체 생성
font_style1= Font(size=12, name='Arial Narrow', bold=True)
side_style1 = Side(border_style="thin", color="000000")
side_style2 = Side(border_style="double")
fill_style1 = PatternFill(start_color="A9CCE3", end_color="A9CCE3", fill_type = "solid")
# [5] 헤더 스타일 지정
for cell in ws['B2':'D2']:
for x in cell:
x.border = Border(top=side_style2, bottom=side_style2)
x.fill = fill_style1
x.font = font_style1
# [6] 본문 스타일 지정
for cell in ws['B3':'D4']:
for x in cell:
x.border = Border(bottom=side_style1)
# [7] 엑셀 파일 저장
wb.save("style_test3.xlsx")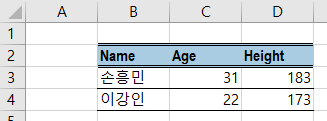
[그림 6-3-11] 셀 테두리 스타일 적용
위 예제에 대해 설명한다.
[1]에서 사용할 모듈을 임포트한다.
[2]에서 Workbook 객체를 생성하고 기본 Worksheet를 가져온다.
[3]에서 각 셀에 값을 입력한다. 문자열인 경우는 따옴표(”)로 둘러 쌓인 문자열을 입력하면 되고, 숫자형이라면 숫자를 바로 입력하면 된다.
[4]에서 각 셀의 스타일에 적용할 스타일 객체를 생성한다. 이렇게 스타일 객체를 변수로 선언해두면 필요한 곳에 편리하게 재활용할 수 있다. Side객체는 외곽선 스타일을 지정할 때 사용하고, PatternFill은 셀의 배경색 스타일을 지정할 때 사용한다. PatternFill이므로 단순히 한 가지 색으로 칠하는 것 보다 고급 기능을 제공한다.
[5]에서 테이블 헤더에 해당하는 셀의 스타일을 지정한다. 지정할 스타일의 범외 혹은 리스트를 for 문에 전달하면 각 셀에 대해 반복적으로 스타일을 적용할 수 있다. 여기서는 위와 아래 외곽선에 이중선 스타일을 적용한다.
[6] 테이블 본문에 해당하는 셀의 스타일을 지정한다. 여기서는 단순히 셀 하단부에 선을 긋도록 한다.
[7]에서 작성한 엑셀을 파일로 저장한다.
참조
셀 외곽선 스타일에 대한 보다 자세한 내용
셀의 배경 스타일을 지정하는 보다 자세한 내용
수식을 입력하는 방법에 대해 설명한다. 셀에 수식을 입력하려면 셀 값을 지정할 때 앞에 등호(’=’)를 넣고 소식을 문자열로 입력하면 된다.
형식 | worksheet[cell_position] = equation_string |
|---|---|
파라미터 | • worksheet : 워크시트 객체를 전달한다. |
예시 | # A1 위치의 셀에 A2부터 A10까지 값의 평균을 계산하는 수식 입력 |
다음은 위에서 작성한 내용에 추가로 나이와 키의 평균을 구하는 수식을 추가하는 예시이다.
[예제 6- 72] 셀에 수식 추가하기
# [1] 모듈 임포트
from openpyxl import Workbook
from openpyxl.styles import Border, Side
from openpyxl.styles import PatternFill
from openpyxl.styles.colors import Color
# [2] Workbook 개체 생성, 기본 Worksheet 얻어오기
wb = Workbook()
ws = wb.active
# [3] 셀에 값 입력
ws["B2"].value = "Name"
ws["C2"].value = "Age"
ws["D2"].value = "Height"
ws["B3"].value = "손흥민"
ws["B4"].value = "이강인"
ws["C3"].value = 31
ws["C4"].value = 22
ws["D3"].value = 183
ws["D4"].value = 173
# [4] 나이와 키 평균 수식 넣기
ws["B5"].value = "평균"
ws["C5"].value = "=AVERAGE(C3:C4)"
ws["D5"].value = "=AVERAGE(D3:D4)"
# [5] 엑셀 파일 저장
wb.save("style_test4.xlsx")[결과]
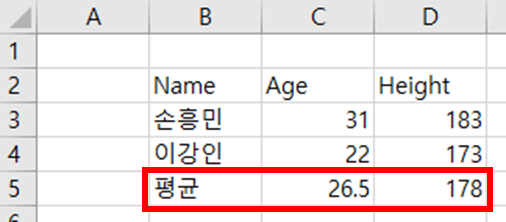
[그림 6-3-12] 엑셀 시트에 폰트 스타일 적용
위 예제에 대해 설명한다.
[1]에서 사용할 모듈을 임포트한다.
[2]에서 Workbook 객체를 생성하고 기본 Worksheet를 가져온다.
[3]에서 각 셀에 값을 입력한다.
[4]에서 수식을 입력한다. 수식을 입력할 때는 실제 엑셀에 입력하는 것과 동일하게 입력하면 되고 수식을 의미하는 등호(’=’)를 맨 앞에 꼭 붙여야 한다. 주의할 점은 수식이 오류가 있으면 해당 내용이 입력되지 않으므로, 미리 수식에 오류가 없는지 확인하고 입력하시기 바란다.
[5]에서 작성한 엑셀을 파일로 저장한다.
여러 개의 셀을 하나로 합칠 때는 Worksheet의 merge( ) 함수를 사용한다.
형식 | worksheet.merge(cell_range) |
|---|---|
파라미터 | • cell_range : 셀 범위를 지정하는 문자열로 "시작셀위치:끝셀위치" 형식으로 지정한다. |
예시 | # 셀 A1부터 C1까지 3개의 셀을 병합 |
다음은 셀을 병합하는 예제이다.
[예제 6- 73] 셀 병합하기
# [1] 모듈 임포트
from openpyxl import Workbook
from openpyxl.styles import Border, Side
from openpyxl.styles import PatternFill
from openpyxl.styles.colors import Color
# [2] Workbook 개체 생성, 기본 Worksheet 얻어오기
wb = Workbook()
ws = wb.active
# [3] 셀을 병합하고 제목 입력
ws.merge_cells("B2:D2")
ws["B2"].value = "대한민국 축구선수"
ws["B2"].font = Font(size=14, name='굴림', bold=True)
ws['B2'].alignment = Alignment(horizontal='center', vertical='center')
# [4] 셀에 값 입력
ws["B3"].value = "Name"
ws["C3"].value = "Age"
ws["D3"].value = "Height"
ws["B4"].value = "손흥민"
ws["B5"].value = "이강인"
ws["C4"].value = 31
ws["C5"].value = 22
ws["D4"].value = 183
ws["D5"].value = 173
# [5] 나이와 키 평균 수식 넣기
ws["B6"].value = "평균"
ws["C6"].value = "=AVERAGE(C4:C5)"
ws["D6"].value = "=AVERAGE(D4:D5)"
# [6] 엑셀 파일 저장
wb.save("style_test6.xlsx")[결과]
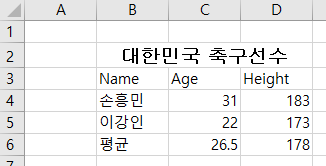
[그림 6-3-13] 셀 합치기 결과
위 예제에 대해 설명한다.
[1]에서 사용할 모듈을 임포트한다.
[2]에서 Workbook 객체를 생성하고 기본 Worksheet를 가져온다.
[3]에서 셀을 병합한다. 범위는 B2 ~ D2까지 3개의 셀이다. 첫 번째 셀인 B2에 문자열을 입력하고 폰트 스타일을 적용하고 중앙 정렬을 한다.
[4]에서 각 셀에 값을 입력한다.
[5]에서 수식을 입력한다.
[6]에서 작성한 엑셀을 파일로 저장한다.
저장된 엑셀 파일은 다음과 같다. B2~D2까지 셀이 하나의 셀로 합쳐진 것을 확인할 수 있다.
참고
판다스 read( ) 함수: 홈페이지 바로가기