
1. 함수 Last updated: 2023-10-17 10:29:44
함수는 호출되어야만 실행되는 코드들의 블럭이며 파이썬의 함수는 이름과 인자들로 구성된다. 함수를 이용하면 필요한 곳에서 호출해 사용할 수 있으므로 코드의 생산성이 증가되고, 관리가 용이해 진다.
함수는 호출되어야만 실행되는 코드들의 블럭이며 파이썬의 함수는 이름과 인자들로 구성된다. 함수를 이용하면 필요한 곳에서 호출해 사용할 수 있으므로 코드의 생산성이 증가되고, 관리가 용이해 진다.
파이썬은 다른 언어들과 다르게 함수를 정의할 때 반환값을 같이 적지 않으며, 한 개 이상의 반환값을 가질 수 있다. 파이썬 함수의 기본 형식은 다음과 같다.
형식 | def function_name(arg1, arg2, …): |
|---|---|
파라미터 | • arg1, arg2, …: 함수의 인자, 함수 호출 시 넘겨 받는 값 |
파이썬 함수의 특징을 정리하면 다음과 같다.
함수 정의는 def 라는 예약어로 함수 정의가 시작함을 알린다.
함수명을 입력한다. 파이썬은 함수명에서 대소문자를 구분한다. 같은 이름이지만 대소문자가 다르면 다른 함수로 인식한다.
인자는 함수명 뒤 괄호(’( )’) 사이에 쉼표(,)로 구분하여 입력한다.
함수 정의가 끝나면 마지막에 콜론(:)을 입력한다.
함수의 코드의 시작 앞에 들어쓰기(보통 공백 4개)를 한다.
반환값이 있는 경우 return 예약어와 함께 입력하고, 반환값이 여러 개인 경우 쉼표로 구분한다. 반환값이 없을 경우 return은 작성하지 않아도 된다.
다음은 인자도 없고 반환 값도 없는 기본적인 함수의 예제이다.
[예제 5- 1] 간단한 함수 정의와 사용하기
# [1] 함수 정의
def say_hello():
# [2] 함수 내용
print("Hello everyone!")
# [3] 함수 호출
say_hello()[결과]
Hello everyone!위 예제에 대해 설명한다.
[1]에서 함수를 정의했다.
[2]부터가 함수의 내용이다. 앞에 공백이 있는 것을 확인한다. 이 함수는 반환값이 없기 때문에 return 문은 존재하지 않는다.
[3]에서 함수를 호출한다. 인자를 넘겨주거나 반환값을 받지는 않지만 함수 내에서 실행된 출력 문자가 표시된다.
다음은 인자로 두 개의 숫자를 입력받고 두 숫자의 차이를 반환하는 diff( ) 함수의 예제이다.
[예제 5- 2] 인자와 반환값이 있는 함수 사용하기
# [1] 함수 정의
def diff(a, b):
# [2] 함수 내용
d = abs(a - b)
# [3] 함수 반환
return d
# [4] 함수 호출
d = diff(10, 12)
print(f"두 값의 차이는 {d} 이다.")[결과]
두 값의 차이는 2 이다.위 예제를 설명한다.
[1]에서 함수를 정의 했다. def로 함수 정의의 시작을 알리고, 함수 이름은 diff( ) 이다. 인자로는 a와 b 두 개를 전달 받는다. 마지막은 ‘:’로 함수 정의했다.
[2]부터가 함수의 실제 실행할 내용이다. 두 인자 a와 b의 절대값을 계산한다.
[3]에서 계산한 d 값을 반환한다. 이로써 함수의 정의와 구현이 끝이다.
[4]에서 정의한 함수를 호출한다. a와 b의 인자가 받을 수 있도록 10과 12 값을 넘겨준다. 함수에서 반환된 값을 d 변수에 = 연산자를 통해 할당한다.
함수에 정의하는 인자에는 기본 값을 설정할 수 있다. 기본값은 할당 연산자(=)를 이용해 값을 지정한다.
단, 기본값을 설정할 때는 몇 가지 조건이 있다.
함수를 호출할 때 기본값이 있는 인자의 값을 입력하지 않으면 함수에 정의된 기본 값이 사용된다.
함수를 호출할 때 기본값이 있는 인자이더라도 값을 입력하면 기본 값은 무시되고 입력한 값이 사용된다.
정의할 때 기본 값이 없는 인자를 앞에 위치시키고, 기본 값이 있는 인자를 뒤에 위치 시켜야 한다.
다음은 제곱승에 해당하는 값을 계산하는 함수 예제이다. 두 번째 인자인 m의 기본값이 2이다.
[예제 5- 3] 인자의 기본값이 있는 함수 사용하기
# [1] 함수 정의. 두 번째 인자 기본 값이 2
def square_power(a, m=2):
# [2] 제곱승 계산
v = pow(a, m)
# [3] 결과 반환
return v
# [4] m값 입력 없이 함수 호출
print("5의 제곱:", square_power(5))
# [5] m값 입력 없이 함수 호출
print("5의 2제곱:", square_power(5, 3))[결과]
5의 제곱: 25
5의 2제곱: 125위 예제에 대해 설명한다.
[1]에서 함수를 정의하였다. 첫 번째 a 값은 입력을 받아야 하고, 두 번째 m 값은 기본값이 2이다.
[2]에서 함수 내용이 실행된다.
[3]에서 return 으로 반환한다.
[4]에서는 첫 번째 인자 a의 값으로 5를 전달하였고, 두 번째 인자는 값을 넣지 않았다. 이렇게 square_power( ) 함수를 호출하면 m값은 기본값인 2가 할당되어 [2]에서 5의 2제곱승 한 값이 계산된다.
[5]에서 보면 첫 번째 인자는 동일하지만 이번에는 두 번째 인자인 m값을 3으로 입력하였다. 이렇게 하면 [2]에서 5의 3제급승 값이 계산된다.
기본 인자가 여러 개인 경우 그 중에 특정 인자 값만 입력할 수도 있다. 다음과 같이 함수를 호출할 때 인자 이름을 입력하고 값을 할당한다.
[예제 5- 4] 기본값이 있는 여러 개의 인자를 갖는 함수 사용하기
# [1] 함수 정의. apple은 필수 입력, banana와 orange는 기본값이 있는 선택 인자
def add_fruit(apple, banana=0, orange=0):
# [2] 모든 과일 갯수를 더한다.
fruit_num = apple + banana + orange
return fruit_num
print("(1) 과일 갯수:", add_fruit(10))
print("(2) 과일 갯수:", add_fruit(10, 0, 5))
print("(3) 과일 갯수:", add_fruit(10, orange=5))
print("(4) 과일 갯수:", add_fruit(10, orange=5, banana=5))[결과]
(1) 과일 갯수: 10
(2) 과일 갯수: 15
(3) 과일 갯수: 15
(4) 과일 갯수: 20위 예제에 대해 설명한다.
[1]에서 함수를 정의한다. 인자 중 apple은 필수 입력이고, banana와 orange는 옵션으로 기본값은 0이다. (1)번에서 apple만 값을 10으로 입력하고 나머지는 입력하지 않아 기본값 0이 banana와 orange변수에 할당되었다. (2)에서 apple, banana, orange변수 값을 모두 입력하였다. 다만, banana는 0이기 때문에 입력할 필요는 없었지만 세 번째 orange값을 입력하기 위해 같이 입력하였다. (3)에서 apple은 값을 입력하였고, banana는 필요 없고 orange만 값을 입력하면 되므로 변수명 orange와 함께 값을 입력하였다. (4)에서 모든 인자의 값을 입력하지만 기본 값을 갖는 banana와 orange변수의 값을 이름과 함께 넘겨주므로 순서는 상관이 없다.
다음은 인자 기본값을 잘못 사용한 예이다.
[예제 5- 5] 인자의 기본값이 잘못 정의된 함수 사용하기
# [1] 함수 정의
def square_power(m=2, a):
v = pow(a, m)
return v[결과]
SyntaxError: non-default argument follows default argument위의 예제에서는 첫 번째 인자에 기본값이 있고 두 번째 인자에 기본값이 없어서 오류가 발생했다. 기본 값이 없는 인자는 기본값이 있는 인자보다 앞에 와야 한다.
파이썬에서는 함수의 반환값을 여러 개 넘겨줄 수 있다. 이는 다른 언어에서는 지원하지 않는 특별한 점이다. 변수가 여러 개일 때는 아래와 같이 변수를 쉼표(,)로 구분하여 나열해 값을 받아온다.
형식 | var1, var2, … = my_func( ) |
|---|---|
파라미터 | • my_func : 함수 이름 |
다음은 함수의 반환값이 3개인 예제이다. return 명령어 뒤에 반환할 값을 순서대로 쉼표(,)로 구분하여 적어준다.
[예제 5- 6] 반환 값이 여러 개인 함수 사용하기
def fruit_count():
# [1] 여러개 값 반환
return 10, 11, 9
# [2] 여러개 값을 순서대로 각 변수에 할당
apple, banana, orange = fruit_count()
print("apple:", apple)
print("banana:", banana)
print("orange:", orange)[결과]
apple: 10
banana: 11
orange: 9위 예제에 대해 설명한다.
[1]에서 함수에서 실행한 결과 값을 순서대로 3개 값을 반환한다.
[2]에서 함수 호출 후 반환되는 값을 받을 변수를 쉼표로 구분하여 순서대로 나열하고 값을 받아온다.
Hint! 반환 후 사용하지 않는 변수는?
파이썬에서는 변수 이름을 적을 때 한 가지 관습이 있다. 여러 개의 값을 한 번에 반환하는 함수의 경우 반환한 값 중에 사용할 필요가 없는 경우도 변수명을 적어줘야 한다. 파이썬에서는 이러한 경우 관습적으로 밑줄(_)를 사용한다. 다시 말해 밑줄로 적혀 있는 변수는 별 관심이 없는 임시 변수명 이구나 라고 이해하면 된다.
# apple 갯수 이외 다른 과일 갯수는 사용하지 않는다.
apple, _, _= fruit_count() print("apple count:", apple)파이썬은 변수 유형을 지정하는 정적 타입이 아니라 데이터 유형에 따라 변형 가능한 동적 타입을 지향한다. 따라서 다른 언어와 같이 변수 타입에 제한 하지 않는다. 하지만, 코드를 작성하는데 있어 변수 타입이 어떤 유형을 고려하여 함수가 만들어 졌는지 안다면 개발에 도움이 될 것이다. 파이썬의 타입 힌트는 3.5부터 지원되기 시작했다. 다음과 같이 함수의 인자에 타입을 힌트로 입력하고, 함수 반환값으로 예상되는 타입을 적어둘 수 있다. 물론 힌트는 힌트일 뿐이므로 가독성을 높이는 용도이고, 이 때문에 코드가 다르게 동작하지 않는다.
함수 힌트의 형식은 다음과 같다.
인자 힌트는 인자 뒤에 콜론(:)을 입력하고 타입 힌트를 입력한다. 타입 힌트는 int, float, str과 같은 직접적인 타입을 적을 수도 있고 문자열(예: ‘정수형 갯수’)을 입력할 수도 있다.
반환 타입 힌트는 함수의 인자 정의를 위한 괄호 ( )가 끝난 뒤에 화살표(->)를 입력하고 그 다음에 타입 힌트를 작성한다.
타입 힌트까지 작성이 끝나면 함수 정의의 끝을 알리는 콜론(:)을 입력한다.
함수 내에서는 타입 힌트와 관계 없이 원하는 코드를 작성한다.
형식 | def my_func(arg1: arg1 hint, arg2: arg2 hint) → return hint: |
|---|---|
파라미터 | • my_func : 구현하는 함수의 이름 |
반환 | val1, val2 : 함수 내에서 return을 통해 반환하는 객체로 반환값이 없을 수도 있고, 여러개를 반환할 수도 있다. |
다음은 함수 인자에 타입 힌트를 입력하는 예시이다.
[예제 5- 7] 함수 인자와 반환 값에 힌트 입력하기
# [1] 함수 정의
def apple_info(apple:int) -> str:
# [2] 인자로 입력한 정보를 출력
info_str = "사과의 갯수는 {} 개 이다.".format(apple)
print(info_str)
# [3] 문자열 반환
return info_str
# [4] 인자 타입에 맞는 정수를 입력
str_out = apple_info(10)
# [5] 인자 타입과 다른 문자열을 입력
str_out = apple_info("apple")[결과]
사과의 갯수는 10 개 이다.
사과의 갯수는 apple 개 이다.위 예제에 대해 설명한다.
[1]에서 함수를 정의하는데 인자 apple이 int 형이라는 것을 힌트로 입력한다. 그리고 반환 타입은 문자열(str)로 힌트를 작성했다.
[2]에서 입력한 인자를 이용해 문자열을 생성하고 출력한다.
[3]에서 생성한 문자열을 반환하고 함수를 종료한다.
[4]에서는 타입에 맞게 정수 10을 인자 값으로 지정하고 함수를 호출 했다.
[5]에서는 타입과 다른 문자열을 인자 값으로 지정하고 함수를 호출 했다. 하지만 오류가 발생하지는 않았다. 함수 호출에는 문제가 없다.
위 예제에서 코드 힌트와 상관 없이 숫자나 문자열을 입력하더라도 오류가 발생하지 않았다. 인자 타입과 상관 없는 내용이 구현되어 있기 때문이다. 하지만 함수 내에서 apple을 숫자라고 가정하고 코드를 작성한 것이 있다면 오류가 발생하거나 다르게 동작했을 수 있다.
[예제 5- 8] 인자 타입을 잘못 사용한 예
# [1] 함수 정의
def apple_total_price(apple:int, price=100) -> int:
# [2] 총 가격
total = apple*price
# [3] 인자로 입력한 정보를 출력
info_str = "사과의 가격은 {}원 이다.".format(total)
print(info_str)
# [4] 총 가격 반환
return total
# [5] 인자 타입에 맞는 정수를 입력
total = apple_total_price(2)
# [6] 인자 타입과 다른 문자열을 입력
total = apple_total_price("apple")[결과]
사과의 가격은 200원 이다.
사과의 가격은 appleappleappleappleappleappleappleappleappleappleappleappleappleap
pleappleappleappleappleappleappleappleappleappleappleappleappleappleappleappleap
pleappleappleappleappleappleappleappleappleappleappleappleappleappleappleappleap
pleappleappleappleappleappleappleappleappleappleappleappleappleappleappleappleap
pleappleappleappleappleappleappleappleappleappleappleappleappleappleappleappleap
pleappleappleappleappleappleappleappleappleappleappleappleappleappleappleappleap
pleappleappleappleappleappleapple원 이다.위 예제에 대해 설명한다.
[1]에서 함수를 정의한다. apple은 정수형이고 price의 기본값은 1000이다. 반환 타입은 문자열이다.
[2]에서 사과의 총 가격을 계산한다.
[3]에서 입력된 사과 갯수와 가격을 곱하여 가격 합계를 계산하는 문자열을 생성한다.
[4]에서 계산된 가격을 반환한다.
[5]에서 사과 갯수를 2개로 입력했다. 1개 당 가격이 100원이므로 ‘사과의 가격은 200원 이다.’ 라고 정상적으로 출력 되었다.
[6]에서는 인자 타입과 다르게 문자열을 입력했다. 여기서는 [2]에서 문자열 x 100이 total 값이 되는데 파이썬에서 문자열 x 숫자는 문자열을 숫자만큼 반복해서 문자열을 생성하라는 의미이다. 따라서 두 번째 결과는 apple 이라는 문자열을 100번 반복한 결과가 얻어졌다. 아마도 이는 예상했던 결과가 아닐 것이다.
Hint! 함수 내에서 타입 검사
함수 내에서 인자 타입이 원하는 값이 아닌 경우 파이썬이 자동으로 오류를 발생 시키지 않기 때문에 이를 감지하려면 assert 문을 사용해 개발자가 직접 검사를 해야 한다. 다음 예제는 assert 문에 원하는 인자 유형을 검사하고, 맞지 않을 경우 문자를 출력하고 Exception을 발생시킨다.
# [1] 함수 정의
def my_function(number:int):
# [2] 조건에 맞지 않을 경우 Exception Error 발생
assert type(number) == int, " number가 int 타입이 아닙니다"
return number
asset 문의 사용은 다음과 같다.
assert 조건문, 조건문이 False일때 출력할 문자열파이썬에서는 import 하지 않더라도 사용할 수 있는 기본 내장(built-in) 함수들이 있다. 몇몇은 이미 앞에서 사용해 보았을 것이다. 이 함수들은 파이썬 개발을 할 때 자주 반복적으로 사용되는 내장 함수들이니 어떤 함수들이 있는지 확인해 보시기 바란다. 내장 함수는 파이썬의 문서를 확인해 보시기 바란다.
람다는 표현식을 이용해 간단히 익명 함수를 만들어 주는 방법이다. 람다 표현식은 복잡한 구문이 아니라 보통 입력한 매개변수들을 활용한 수식을 작성하는데 사용하므로 표현식 이라고 한다. 람다를 작성하는 방법을 알아보자. 함수로 구현된 내용을 람다식으로 구현해 본다. 다음은 입력된 값을 제곱해서 반환하는 함수이다.
[예제 5- 9] 제곱을 구하는 간단한 함수 구현하기
# [1] 함수 선언
def pow2(a:int):
# [2] 입력 값을 서로 곱해서 반환
return a * a
# [3] 함수 호출
pow2(12)[결과]
144위의 예제를 람다식으로 구현해 본다. 결과는 위와 동일하다.
[예제 5- 10] 제곱을 구하는 람다 함수로 구현하기
# [1] 함수 선언
pow2 = lambda a : a*a;
# [2] 함수 호출
pow2(12)[결과]
144위 예제에 대해 설명한다.
[1]에서 람다식 한줄로 두 값을 곱해 반환하는 익명 함수를 pow2라는 이름으로 구현하였다. 이전 함수로 구현할 때 보다 간략화된 것을 확인할 수 있다.
[2]에서 생성된 람다식을 매개변수를 입력하고 함수와 동일하게 호출한다. 입력된 매개변수는 [1]의 lambda의 매개변수 부분에 a와 매핑된다.
다음은 람다식을 딕셔너리로 구성된 리스트를 정렬하는 방법이다. 사실 방법은 직전에 sorted( ) 함수를 사용해 정렬한 방식과 동일하고 대신 내장 함수 min( ), max( )를 사용한 것만 다르다. 아래 예시를 보면 리스트의 각 항목은 딕셔너리로 구성되어 있고, 거기에는 name, count와 같은 속성들 값이 존재한다. 이 집합 데이터에 대해 특정 속성을 기준으로 정렬할 때 람다 함수를 사용할 수 있다.
[예제 5- 11] 리스트에 람다 함수 적용하기
# [1] 딕셔너리로 구성된 리스트
fruit_counts = [{'name': 'banana', 'count': 4},
{'name': 'apple', 'count': 8},
{'name': 'melon', 'count': 5},
{'name': 'orange', 'count': 12}]
# [2] 람다 함수를 이용해 정렬
sorted(fruit_counts, key=lambda x: x['name'])[결과]
[{'name': 'apple', 'count': 8},
{'name': 'banana', 'count': 4},
{'name': 'melon', 'count': 5},
{'name': 'orange', 'count': 12}]위 예제에 대해 설명한다.
[1]에서 name과 count 속성을 갖는 딕셔너리들로 구성된 리스트를 정의한다.
[2]에서 내장된 sorted( ) 함수를 이용해 데이터를 정렬한다. 이 때 key 매개변수에 람다함수를 지정하는데, 람다 함수는 입력된 딕셔너리 항목에서 name 값을 반환한다. 이렇게 되면 fruit_counts는 name 값으로 오름차순 정렬되어 리스트를 반환한다.
다음 예제는 count 속성을 기준으로 내림차순 정렬하는 예제이다.
[예제 5- 12] 딕셔너리에 람다 함수 적용하기
# [1] 딕셔너리로 구성된 리스트
fruit_counts = [{'name': 'banana', 'count': 4},
{'name': 'apple', 'count': 8},
{'name': 'melon', 'count': 5},
{'name': 'orange', 'count': 12}]
# [2] 람다 함수를 이용해 정렬
sorted(fruit_counts, key=lambda x: x['count'], reverse=True)[결과]
[{'name': 'orange', 'count': 12},
{'name': 'apple', 'count': 8},
{'name': 'melon', 'count': 5},
{'name': 'banana', 'count': 4}]위 예제에 대해 설명한다.
[1]에서 name과 count 속성을 갖는 딕셔너리들로 구성된 리스트를 정의한다.
[2]에서 내장된 sorted( ) 함수를 이용해 데이터를 정렬한다. 이 때 key 매개변수에 람다함수를 지정하는데, 람다 함수는 입력된 딕셔너리 항목에서 count 값을 반환한다. 그리고 reverse 매개벼수를 True로 지정하여 내림차순 정렬이 되도록 한다. 이렇게 되면 fruit_counts는 count 값이 큰 순으로 내림차순 정렬되어 리스트를 반환한다.
여러 개의 딕셔너리로 구성된 리스트가 있을 때 특정 속성을 기준으로 최대 혹은 최소 값에 해당하는 딕셔너리를 찾는 방법에 예제를 통해 알아보자.
[예제 5- 13] 람다함수로 딕셔너리 최대 최소 구하기
# [1] 딕셔너리로 구성된 리스트
fruit_counts = [{'name': 'banana', 'count': 4},
{'name': 'apple', 'count': 8},
{'name': 'melon', 'count': 5},
{'name': 'orange', 'count': 12}]
# [2] 람다 함수를 이용해 name에서 맨앞/맨뒤 항목 찾기
print("name 순으로 첫 번째 항목:", min(fruit_counts, key=lambda x: x['name']))
print("name 순으로 마지막 항목:", max(fruit_counts, key=lambda x: x['name']))
# [3] 람다 함수를 이용해 count 값이 가장 작고/큰 항목 찾기
print("count 값이 가장 작은 작은 항목:", min(fruit_counts, key=lambda x: x['count']))
print("count 값이 가장 큰 항목:", max(fruit_counts, key=lambda x: x['count']))[결과]
name 순으로 첫 번째 항목: {'name': 'apple', 'count': 8}
name 순으로 마지막 항목: {'name': 'orange', 'count': 12}
count 값이 가장 작은 작은 항목: {'name': 'banana', 'count': 4}
count 값이 가장 큰 항목: {'name': 'orange', 'count': 12}람다식을 빌트인 함수인 filter와 함께 사용하여 집합 데이터를 필터링 하는 방법에 대해 설명한다. 우선 필터 함수의 형식은 다음과 같다. 첫 번째 매개 변수가 함수이고, 두 번째 함수가 반복 가능한 데이터이다.
형식 | filter(function, iterable) |
|---|---|
파라미터 | • function : 집합 객체를 필터링 하기 위한 함수로 True 혹은 False에 해당하는 값을 반환하는 함수 |
반환 | (object) 필터링 된 집합 객체 |
여기에 첫 번째 함수 부분에 람다 함수를 사용하면 람다 함수를 이용해 필터링을 수행할 수 있다. 람다 함수 수행 결과는 True 혹은 False가 되도록 작성한다.
다음은 숫자 리스트 중에서 3의 배수인 값을 찾아 리스트로 반환하는 예제이다.
[예제 5- 14] 람다함수로 filter 실행하기
# [1] 숫자형 리스트 생성
my_numbers = [1, 3, 5, 7, 9, 10, 11, 15]
# [2] filter 빌트인 함수 호출
result = list(filter(lambda x: (x % 3 == 0), my_numbers))
print(result)[결과]
[3, 9, 15]위 예제에 대해 설명한다.
[1]에서 숫자로 구성된 리스트를 생성한다.
[2]에서 람다 함수를 선언하고 조건 부분에 3의 배수가 되는 경우 True가 반환 되도록 작성한다. 이렇게 하면 실제 반환되는 값은 [False, True, False, False, True, False, False, True]가 될 것이다. filter 함수는 이 값을 이용해 True에 해당하는 [3, 9, 15]를 반환하고, 이를 list( ) 함수를 이용해 리스트로 캐스팅 한다.
다음은 딕셔너리들로 구성된 리스트에서 count 값이 7보다 큰 항목을 필터링 하는 예제이다.
[예제 5- 15] 딕셔너리에서 람다함수로 filter 실행하기
# [1] 딕셔너리로 구성된 리스트
fruit_counts = [{'name': 'banana', 'count': 4},
{'name': 'apple', 'count': 8},
{'name': 'melon', 'count': 5},
{'name': 'orange', 'count': 12}]
# [2] filter 빌트인 함수 호출
result = list(filter(lambda x: (x['count'] > 7), fruit_counts))
print(result)[결과]
[{'name': 'apple', 'count': 8}, {'name': 'orange', 'count': 12}]위 예제에 대해 설명한다.
[1]에서 딕셔너리들로 구성된 리스트를 생성한다.
[2]에서 람다 함수를 선언하고 조건 부분에 count 속성 값이 7보다 큰 경우 True가 되도록 작성한다. 이렇게 하면 실제 반환되는 값은 [False, True, False, True]가 될 것이다. filter 함수는 이 값을 이용해 True에 해당하는 1번과 3번 항목을 가져와 list( ) 함수를 이용해 리스트로 생성한다.
내장 함수 map을 이용해 여러 개의 집합 데이터를 원하는 형태로 재구성하는 방법에 대해 설명한다. 길이가 동일한 집합 데이터가 여러 개 있을 경우 각각 동일한 인덱스의 데이터를 하나씩 불러와서 원하는 조건에 따라 조작한 후 리스트를 구성할 수 있다. 다음의 그림을 보고 이해해 보자. 리스트 a와 리스트 b는 map에 입력으로 전달되고 map 이 순환하면서 a의 0번 값인 1과 b의 0번 값인 10을 꺼내 람다 함수로 전달한다. 그러면 람다 함수는 a와 b의 값을 수식에 의해 곱하고 반환한다. 이렇게 총 5번 진행하면서 람다 함수를 통해 실행된 값이 저장된 map 객체가 생성되고, 이를 리스트 변환하여 리스트 c를 생성한다.
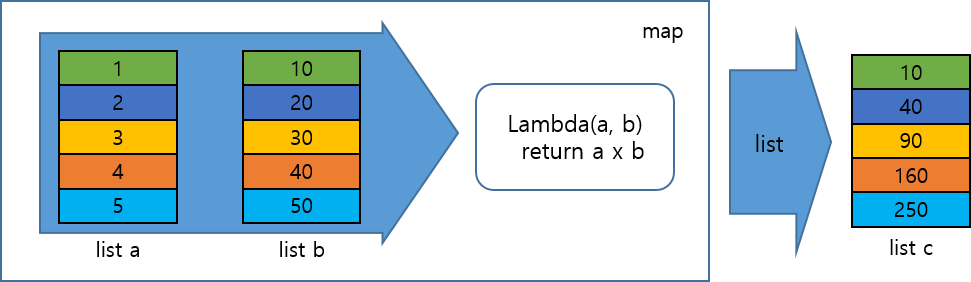
[그림 5-1-1] 람다 함수 실행 과정
다음 예제를 살펴보자.
[예제 5- 16] 람다에서 map을 이용해 새로운 리스트 집합 생성하기
# [1] 리스트 변수 생성
list_a = [1, 2, 3, 4, 5]
list_b = [10, 20, 30, 40, 50]
# [2] 람다 함수 이용 map 생성
map_c = map(lambda a, b: a*b, list_a, list_b)
# [3] map을 list 집합으로 변환
list_c = list(map_c)
print(list_c)[결과]
[10, 40, 90, 160, 250]위 예제에 대해 설명한다.
[1]에서 두 개의 리스트 객체 list_a와 list_b를 생성한다.
[2]에서 람다 함수를 이용해 map을 생성한다. 람다 함수의 수식은 a x b 이다.
[3]에서 맵 객체를 리스트 객체로 변환한다.