7장. 자연어 처리 Last updated: 2023-03-04 15:49:57
다양한 자연어 방법에 대해 설명합니다. 자연어 처리를 위해서는 텍스를 전처리하고, 토크나이저로 단어와 조사 등 최소 단위로 분해하고 이를 이용해 전체 문장 구조를 분석하는 것부터 시작합니다. 또한 여러 ML/DL 알고리즘들을 이용해 분장 분류, 번역, 챗봇 등 다양한 응용 서비스를 만들 수 있습니다.
다양한 자연어 방법에 대해 설명합니다. 자연어 처리를 위해서는 텍스를 전처리하고, 토크나이저로 단어와 조사 등 최소 단위로 분해하고 이를 이용해 전체 문장 구조를 분석하는 것부터 시작합니다. 또한 여러 ML/DL 알고리즘들을 이용해 분장 분류, 번역, 챗봇 등 다양한 응용 서비스를 만들 수 있습니다.
NLC, Entity와 Dialog(Flow)를 결합하여 질문에 대답을 하는 자연어 기반 챗봇 엔진
https://www.nltk.org/
NLTK는 파이썬 환경에서 사용하기 쉽게 자연어 처리를 실행해 볼 수 있는 오픈소스 (Apache License Version 2.0) 라이브러리이다.
Classification, tokenization, stemming, tagging, parsing, semantic reasoning 등 자연어 처리 기능을 제공한다.
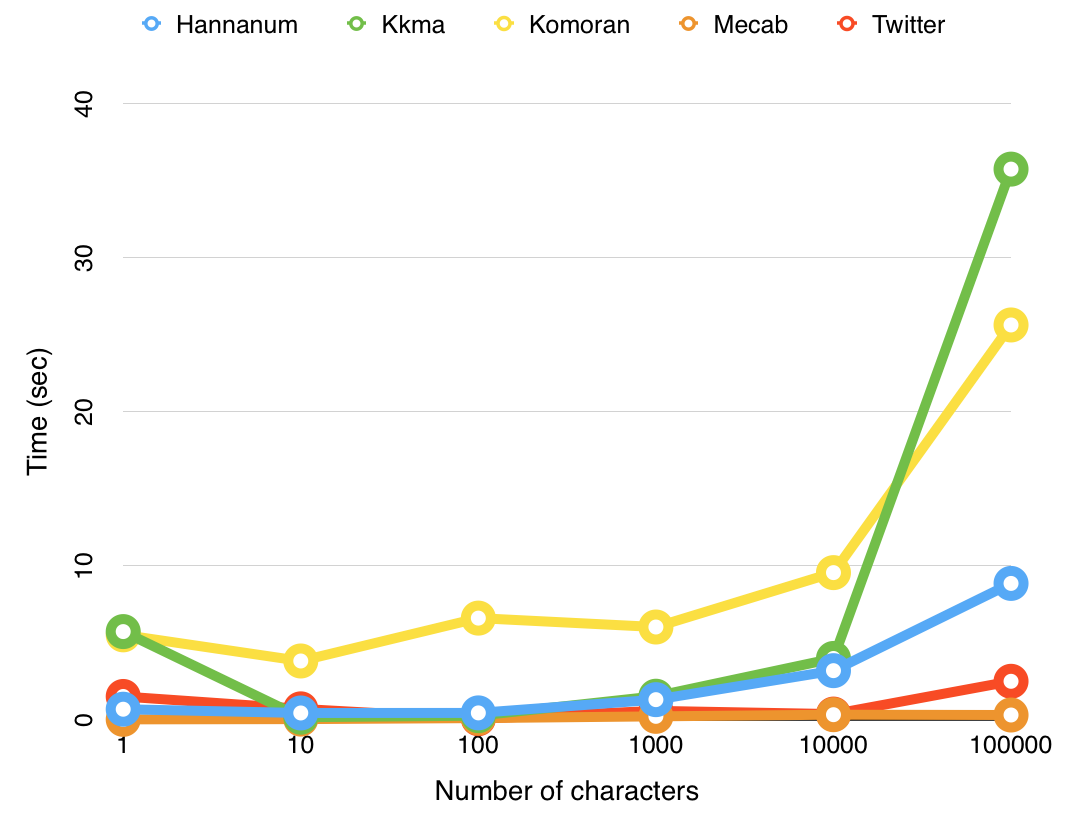
https://konlpy.org/ko/latest/index.html
KoNlpy는 한글 토크나이터를 사용하기 쉽게 wraping한 파이썬 라이브러리이다.
오픈소스이며 GPL v3 혹은 그 이상의 라이센스를 갖습니다.
KoNlpy는 자체적으로 자연어 처리 엔진을 제공하지 않고, 기존에 개발된 형태소 분석기를 통일된 interface로 제공한다.
지원하는 품사 태깅 클래스
꼬꼬마 (kkma)
코모란 (Komoran)
한나눔 (Hannanum)
Okt (Open Korea Text) : 이전의 트위터 형태소 분석기의 최근 버전이다.
메캅 (Mecab)